In this lesson, you will run a correlation between resting and after-exercising heart rates to determine if a linear relationship exists between the two variables and how strong the relationship is. Steps Open the Heart Rate Data Set in Excel and identify the X-variable (resting heart rates for all 200 participants) and the Y-variable (after-exercise heart rates for all 200 participants). Use the Scatter Plot function in the Insert n of Excel to create a scatter plot of the X and Y variables. Your assignment should be typed into a Word or other word-processing document, formatted in APA style. The assignments must include Running head A title page with Assignment name Your name Professors name Course
Category: Statistics
-
Statistics Question
ATTENDANCE WORKSHEET
Statistical Testing (2)
Requirements: 3 hours
-
Hi pleas I need help for my homework
Progress Check
Use this activity to assess whether you and your peers can:
- Use a five-number summary and a boxplot to describe a distribution.
- Recognize the median as the center between two equally-sized groups within a distribution of data.
- Use the IQR to describe the spread for the middle 50% of a data set.
- Recognize the limitations of a boxplot.
Directions
Use the drop-down menu to learn about the three steps needed to complete this assignment.
Three steps to complete the assignment
Step 1: Review the Rubric
- Before you submit your work, review the rubric at the bottom of this assignment.
- Use the rubric as a checklist to determine whether you are ready to submit your work.
Step 2: First Draft
- Commit a good-faith effort to address each item in the Prompt section below.
- Please be sure to number your responses and include “white space” between problem numbers. This improves the readability and flow of your work. I cannot give feedback and grade jumbled work.
- Use either of the following options to submit your work.
OPTION 1: You can submit a text-entry assignment (i.e. typing your answers in Canvas). To learn how to submit a text-entry assignment, use these (opens in a new tab).
OPTION 2: You can upload your paper-and-pencil work (or the digital equivalent). To learn how to upload your paper-and-pencil work, use these (opens in a new tab). WARNING – some file types may not be visible on my end. So to learn which files you can upload, be sure to use the directions link I provided for this option. - Not ready to submit a good-faith effort yet? Avoid frustration – use the link to the Questions, Answers, & Tips discussion board (at the bottom of this page) to post questions about this assignment (or visit the discussion board to answer your classmates’ questions). You can also contact me directly (see the homepage for my contact information).
Step 3: Optional Final Draft
- After you submit your good-faith attempt to fully respond to the questions in the Prompt section below, advance to the ANSWER(S) page.
- You can use the ANSWER(S) page to correct your work and resubmit this assignment any time before I begin grading the problems. However, to earn full credit, you are not required to submit a final draft for this assignment. But if you do submit a final draft, I will only grade it if you submitted a good-faith effort on your first draft.
- Warning – I will only grade your most recent submission. So if you choose to submit a final draft, please do not leave anything out, and please do not direct me to read an earlier submission. To maximize your score, your most recent submission (at the time I begin grading) must be complete.
Context
Here is a boxplot for a distribution of data.
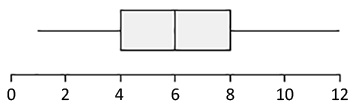
Prompt
- Calculate the IQR for the boxplot shown.
- Make up a data set (n = 10) that has the same minimum value, same median, and same maximum value, but a larger IQR than the boxplot shown. List your data set and then describe your strategy.
- Make up another data set (n = 10) that has the same minimum value, same median, and same maximum value, but a smaller IQR than the boxplot shown. List your data set and then describe your strategy.
Module 9 Discussion Board
Use the Module 9 (opens in a new tab) to ask questions or provide feedback about the problems in any Module 9 activity – including this peer-reviewed assignment.
Review Feedback
- Instructor feedback is only available after an assignment is graded.
- Use these (opens in a new tab) to learn how to review feedback.
Click the “Next” or > button to continue.
Content by Cuyamaca College math faculty and licensed under the .
Rubric
Formative Assessments
Formative Assessments
Criteria Ratings Pts This criterion is linked to a Learning OutcomeAnswering the Prompt
10 pts
Total Points: 10
Requirements: 5 h
-
Statistics course reflection
THIS WAS MADE BY AI TO GIVE YOU INFROMATION ABOUT ME TO WRITE DO NOT USE AI FOR THIS ASSIGNMENT
***************Since youre a travel LPN + run a business + deal with pay/taxes/housing:
You could talk about:
1. Evaluating Healthcare Research
- Now you understand what a p-value means.
- You wont just accept studies show… without questioning sample size.
- In nursing, policies are based on data now you can actually understand it.
2. Travel Nursing Pay & Contracts
- Comparing hourly rates vs. stipends.
- Understanding averages vs. outliers.
- Looking at cost of living data before accepting contracts.
3. Your Business (Velora CX)
- Calculating wages vs. profit margins.
- Understanding trends in hiring.
- Looking at performance metrics instead of just guessing.
4. Real Estate / Housing
You literally just did a housing analysis project.
You can say:
- Now you understand how averages can hide variability.
- A 95% confidence interval makes more sense.
- You see how market claims can be tested instead of assumed.
How Data Analysis Is Changing the World
You could mention:
- Healthcare is heavily data-driven now (readmission rates, infection rates, outcome tracking).
- AI and predictive modeling in hospitals.
- Employers use productivity metrics.
- Social media algorithms are based on data.
- Insurance premiums are data-based.
- Real estate pricing uses predictive analytics.
In your tone, you could say something like:
Everything is tracked now. Hospitals track outcomes, companies track productivity, even social media tracks engagement. Decisions are less opinion-based and more data-driven.
How Statistics Can Be Persuasive or Misleading
This is where you can sound really smart without trying.
Example 1: Risk Doubled
If something goes from 1% to 2%, headlines say:
Risk doubled!
But thats only a 1% absolute increase.
Example 2: Manipulated Graphs
If a graph starts at 90 instead of 0, differences look huge.
Example 3: Small Sample Sizes
A study with 12 people isnt the same as one with 1,000.
Example 4: Averages Hide Spread
If one house sells for $1.5M, it can inflate the average home price.
You could say:
Before this class, I probably would have just accepted numbers at face value. Now I question sample size, distribution, and whether the conclusions actually match the data.
How You Might Answer Do You Look at Statistics Differently Now?
You absolutely can say yes.
Examples:
- You dont just trust headlines.
- You think about sample size.
- You understand confidence levels.
- You recognize that statistically significant doesnt always mean practically significant.
**************************************************************
8-1 Discussion: Reflection
Possible Points: 25
In this course, you learned core applications of statistical analysis to solve real-world personal or professional inquiry problems. You also learned different techniques to draw conclusions from data. These experiences allowed you to practice designing an approach to a statistical problem, considering assumptions and constraints, and developing interpretations and conclusions. Think about how you felt when you first started the course and how you feel now. Reflect on what you learned in this course and the applications of statistical concepts in your personal and professional life.
In your initial discussion post, specifically address the following:
- What are some practical uses in your own life for the skills you gained in this class?
- How is data analysis changing in the world around you, including workplaces?
- How can statistics be persuasive and misleading? Please provide an example.
In your response posts to at least two peers discuss the following:
- Do you look at statistics differently now? If so, how?
- What advice can you offer to help others make the most appropriate use of data?
To complete this assignment, review the
Undergraduate Discussion Rubric
Overview
Your active participation in the discussions is essential to your overall success this term. Discussion questions will help you make meaningful connections between the course content and the larger concepts of the course. These discussions give you a chance to express your own thoughts, ask questions, and gain insight from your peers and instructor.
Directions
For each discussion, you must create one initial post and follow up with at least two response posts.
For your initial post, do the following:
- Write a post of 1 to 2 paragraphs.
- In Module One, complete your initial post by Thursday at 11:59 p.m. Eastern.
- In Modules Two through Eight, complete your initial post by Thursday at 11:59 p.m. of your local time zone.
- Consider content from other parts of the course where appropriate. Use proper citation methods for your discipline when referencing scholarly or popular sources.
For your response posts, do the following:
- Reply to at least two classmates outside of your own initial post thread.
- In Module One, complete your two response posts by Sunday at 11:59 p.m. Eastern.
- In Modules Two through Eight, complete your two response posts by Sunday at 11:59 p.m. of your local time zone.
- Demonstrate more depth and thought than saying things like I agree or You are wrong. Guidance is provided for you in the discussion prompt.
Discussion Rubric
CriteriaExceeds ExpectationsMeets ExpectationsPartially Meets ExpectationsDoes Not Meet ExpectationsValueComprehensionDevelops an initial post with an organized, clear point of view or idea using rich and significant detail (100%)Develops an initial post with a point of view or idea using adequate organization and detail (85%)Develops an initial post with a point of view or idea but with some gaps in organization and detail (55%)Does not develop an initial post with an organized point of view or idea (0%)40TimelinessN/ASubmits initial post on time (100%)Submits initial post one day late (55%)Submits initial post two or more days late (0%)10EngagementProvides relevant and meaningful response posts with clarifying explanation and detail (100%)Provides relevant response posts with some explanation and detail (85%)Provides somewhat relevant response posts with some explanation and detail (55%)Provides response posts that are generic with little explanation or detail (0%)30Clear CommunicationExceeds expectations with an intentional use of language that promotes a thorough understanding (100%)Consistently and effectively communicates in an organized way to a specific audience (85%)Shows progress toward meeting expectations, but communication is inconsistent or ineffective in a way that negatively impacts understanding (55%)Shows no evidence of consistent, effective, or organized communication (0%)20Total:100%
-
Walk Thru Practice using Google Sheets
click this link to see the video instrustions on how to do the assignment.
Below are the photos of the numbers and categories that are to be used for this assignment please put all numbers the way they are formated in the photos in order into a Google sheet!!
the sample dataset provided in the photos you are responsible for calculating the central tendency for every meaningful variable and list the variables you decided to do the calculations for.
written instrustions:
Please create a simple worded script for a video reflection that includes how you calculated the central tendency and looking at the data, what meaning can you find. Use the Meal Plan (m-main idea, e-evidence, a-analysis of what it means to you in your future career as you analyze secondary data, L-link back to your Christian worldview to get full credit. Missing parts of this assignment will be graded for what part of the instructions where followed.
-
Individual assignment
For your individual assignment, please respond fully to the following 2 questions. Be sure and cite in your separate bibliography page. Please paste the questions in the body of your paper and then respond. It is due on Feb. 22 (11:59 p.m.).
1. Define the levels (or scales) of measurement (nominal, ordinal, interval levels) AND provide an example of each [4 points].
2. Please explain “central tendency” as describing “mean”, “median”, and “mode”. Please discuss why it is important to know in statistics and explain how to calculate each value. If necessary, you can use examples [3 points].
3. Although computer software is used to calculate statistics, some students find that hand calculation furthers their conceptual understanding. Consider the following values: 4, 5, 7, 9, 11, 13, 13, 16, and 18. Calculate the mean, median, and mode. Please use Excel to calculate the above statistics and verify them using the computer. (To practice, you can make up your own data, too.) (Please check “Useful resources for individual assignment 1” below before answering this question) [3 points].
* Format:
12pt. Times New Roman, Double-spaced
Either .doc or .pdf form is accepted.
** Useful resources for individual assignment 1
A. To look for simple explanation of various concepts in descriptive statistics and calculation of the three measures of central tendency, you can refer to the descriptive statistics webpage on this website
B. You will be asked to carry out some basic analysis in Excel for this discussion. To install Analysis Toolpack in Excel and learn how to perform descriptive statistics procedures in Excel, please read Chapter 18 (Excel User’s Guide) in the Essential Statistics workbook.
Here is how I would install Analysis Toolpack in Excel
To install the Data Analysis ToolPak in Excel, follow these steps:
- Open an Excel file
- Go to File-Options-click on Add-ins-click on Analysis ToolPak-click OK-In case the Analysis ToolPak is not listed n the Add-Ins Available box, click Browse to locate it. After you load the Analysis ToolPak, the Data Analysis command will be available under the Data tab (on the right-hand side of the menu bar).
C. Please check out this useful video that shows the calculation of descriptive statistics in Excel.
*** Need to know
Please note for the assignments, the following sources are not acceptable for use in this course since they are not confirmed sites: Wikipedia, Fact Monster, Answers.com, About.com, WiseGeek, Yahoo Answers, The Free Dictionary, Merriam Webster online, eNotes, Facebook, Ask.com, Twitter, boundless.com, study.com, coursehero.com, cliffnotes.com, or any similar source which is randomly found on the internet. Note that even Wikipedia has a disclaimer that it cannot be trusted as a valid source: . You should instead use sources found in the course content and also at Odum library that are valid and confirmed. For further assistance, please contact the VSU writing center or a librarian for help.
Attached Files (PDF/DOCX): Chapter20520Slides.pdf, Bowman20and20West20(2021).pdf, Chapter20620Slides.pdf, Chapter20720Slides.pdf
Note: Content extraction from these files is restricted, please review them manually.
-
Discussion Post
Please check out this video that shows the calculation of frequency distribution in Excel: https://www.youtube.com/watch?v=Giewd9yH4q0
1. Use the Public Perceptions data set available in the Module 3 [4 points].
Make a frequency distribution of the variable Cutting Property Taxes (Cuttax). What percentage of residents state that cutting property taxes is very important (3)?
2. Consider the following values: 4, 5, 7, 9, 11, 13, 13, 16, and 18. Calculate the standard deviation. Also, please explain what the standard deviation is, and provide any comments/information related to “standard deviation” that you want to share with your classmates [4 points].Attached Files (PDF/DOCX): Chapter20520Slides.pdf, Bowman20and20West20(2021).pdf, Chapter20620Slides.pdf, Chapter20720Slides.pdf
Note: Content extraction from these files is restricted, please review them manually.
-
Statistics Question
Write a 4 – 5-page research paper on ONE of the topics listed below. Focus on financial issues and include statistics from reputable sources to support your paper. Your paper should include hypothetical solutions to the problems you have presented and the roles HIM professionals can play in these solutions. You are required to use at least 4 peer-reviewed journal articles and/or websites. Reputable websites end in .gov or .org. (AHIMA, CMS, OIG, AHA, AMA, etc. do not use an advertisement page, vendor marketing page, Wikipedia, or blog page).
Use APA format.
Cover page
Double spaced
Times New Roman 10-12 point font
Paper should include an introduction, body with points about the topic, and a summary.
- Mergers – financial impact
- Drug prices – how to lower drug prices while having sufficient funding to continue new drug research
- Cyber security – the cost of health care
- Medical Cost Mystery- why can’t consumers do a price comparison of healthcare facilities. How can this be accomplished?
Your paper should follow APA formatting and be submitted in a Microsoft Word document. See APA formatting instructions posted in the Course Resources Module.
A cover page and works cited page must be included in addition to the 4 – 5 page paper; however, an abstract page is not required. When your paper is first submitted in Canvas, it will run through Turnitin to detect plagiarism. Any final paper indicating more than 20% plagiarism or AI score will receive a zero.
Requirements:
-
discussion
Directions
How much “statistical significance” do you need to feel confident in regression results? What could potentially affect those results and make them misleading, i.e., appear to be stronger than they are? Explain, discuss.
Initial Post
Post your initial response by Thursday at 11:59 p.m. CST.
Response Post
In your response post, respond to at least TWO other classmates. Respond in one or more of the following ways:
- Make a suggestion.
- Share an insight from having read your colleagues posting.
- Expand on your colleagues posting.
This is a total of THREE entries for each unit’s discussion.
-
Statistical Learning I
fnish all questions
{“cells”:[{“cell_type”:”markdown”,”id”:”dceccf8c”,”metadata”:{“id”:”dceccf8c”},”source”:[“# STA142A Homework 5 – Lasso & Ridgen”,”n”,”n”,”### Dr. Lingfei Cuin”,”n”,”n”,”Please complete the missing parts of this notebook. ~~Problem 1 will not be graded. However, you are strongly encouraged to complete them, as these theoretical exercises will deepen your understanding of the underlying methods.~~n”,”n”,”- If the answer cell is a markdown cell, you are expected to type in your answer without any Python codes.n”,”- If the answer cell is a code cell, you are expected to write python codes to answer the problem.n”,”n”,”If the problem involves mathematical derivations, you need to write Latex code to answer it. Help see https://stackoverflow.com/questions/13208286/how-to-write-latex-in-ipython-notebookn”,”n”,”#### Submission Instructionn”,”You can finish this homework either locally or on colab. After you have finished all the problemsn”,”n”,”**Local Clean Re-run**n”,”- Click `Kernel`->`Restart & Run All` to get a clean output.n”,”- Click `File`->`Download as`->`PDF` to get a pdf copy of your finished homework.n”,”n”,”**Colab Clean Re-run**n”,”n”,”- Click `Runtime`->`Restart Session and Run All` to get a clean output.n”,”- Click `File`->`Print`->`save as PDF` to get a pdf copy of your finished homework.n”,”n”,”**Upload to Canvas**n”,”n”,”- Submit the pdf file online before the deadline.”]},{“cell_type”:”markdown”,”id”:”9cd6090a-21bf-4ec6-aa80-3eee8f596a8b”,”metadata”:{“id”:”9cd6090a-21bf-4ec6-aa80-3eee8f596a8b”},”source”:[“### Problem 1 (Lasso, Ridge and Their Bayesian Connection)n”]},{“cell_type”:”markdown”,”id”:”6bc90e15-86e4-47c4-8fac-3b6b1382eaf0″,”metadata”:{“id”:”6bc90e15-86e4-47c4-8fac-3b6b1382eaf0″},”source”:[“We will now derive the Bayesian connection to the lasso and ridge regression.n”,”n”,”(a) Suppose that $y_i=\beta_0+\sum_{j=1}^p x_{i j} \beta_j+\epsilon_i$ where $\epsilon_1, \ldots, \epsilon_n$ are independent and identically distributed from a $N\left(0, \sigma^2\right)$ distribution. Write out the likelihood for the data.n”]},{“cell_type”:”markdown”,”id”:”fd2d6f1a-6b17-4001-a55d-dd81a8198e60″,”metadata”:{“id”:”fd2d6f1a-6b17-4001-a55d-dd81a8198e60″},”source”:[“Answer:n”]},{“cell_type”:”markdown”,”id”:”7bf2c60c-0502-49bf-b3c9-dd0bb0a3c04c”,”metadata”:{“id”:”7bf2c60c-0502-49bf-b3c9-dd0bb0a3c04c”},”source”:[“(b) Assume the following prior for $\beta: \beta_1, \ldots, \beta_p$ are independent and identically distributed according to a double-exponential distribution with mean 0 and common scale parameter $b$ : i.e. $p(\beta)=\frac{1}{2 b} \exp (-|\beta| / b)$. Write out the posterior for $\beta$ in this setting.n”]},{“cell_type”:”markdown”,”id”:”1381e898-6c9e-4cec-a413-8134e1674ed0″,”metadata”:{“id”:”1381e898-6c9e-4cec-a413-8134e1674ed0″},”source”:[“Answer:n”]},{“cell_type”:”markdown”,”id”:”990139bb-d12b-4f3d-80cb-3017aa3df476″,”metadata”:{“id”:”990139bb-d12b-4f3d-80cb-3017aa3df476″},”source”:[“(c) Argue that the lasso estimate is the mode for $\beta$ under this posterior distribution.n”]},{“cell_type”:”markdown”,”id”:”990508df-42a8-4e1e-8112-8b41cac1cfa4″,”metadata”:{“id”:”990508df-42a8-4e1e-8112-8b41cac1cfa4″},”source”:[“Answer:”]},{“cell_type”:”markdown”,”id”:”63fcd1be-0c57-43af-a88c-bbe3a7f7d505″,”metadata”:{“id”:”63fcd1be-0c57-43af-a88c-bbe3a7f7d505″},”source”:[“(d) Now assume the following prior for $\beta: \beta_1, \ldots, \beta_p$ are independent and identically distributed according to a normal distribution with mean zero and variance $c$. Write out the posterior for $\beta$ in this setting.n”]},{“cell_type”:”markdown”,”id”:”38b7e372-3efd-4d77-81a4-de6568c4796b”,”metadata”:{“id”:”38b7e372-3efd-4d77-81a4-de6568c4796b”},”source”:[“Answer:n”,”n”]},{“cell_type”:”markdown”,”id”:”c5f56913-5f7b-4b96-9d0b-1cede99297de”,”metadata”:{“id”:”c5f56913-5f7b-4b96-9d0b-1cede99297de”},”source”:[“(e) Argue that the ridge regression estimate is both the mode and the mean for $\beta$ under this posterior distribution.”]},{“cell_type”:”markdown”,”id”:”22a53d8d-d480-4250-a645-989f15b25372″,”metadata”:{“id”:”22a53d8d-d480-4250-a645-989f15b25372″},”source”:[“Answer:n”]},{“cell_type”:”markdown”,”id”:”40baf850″,”metadata”:{“id”:”40baf850″},”source”:[“### Problem 2 (Lasso, Ridge and OLS)n”,”n”,”In this exercise, we will predict the number of applications received using the other variables in the `College` data set.n”]},{“cell_type”:”markdown”,”id”:”2e807a06″,”metadata”:{“id”:”2e807a06″},”source”:[“(a) Split the data set into a training set and a test set.”]},{“cell_type”:”code”,”execution_count”:null,”id”:”e3bcf492-f122-423c-8307-f50391c8ca2f”,”metadata”:{“id”:”e3bcf492-f122-423c-8307-f50391c8ca2f”},”outputs”:[],”source”:[]},{“cell_type”:”markdown”,”id”:”83f283f5-1a6e-4f07-82c3-1b297ab36efb”,”metadata”:{“id”:”83f283f5-1a6e-4f07-82c3-1b297ab36efb”},”source”:[“(b) Fit a linear model using least squares on the training set, and report the test error obtained.n”]},{“cell_type”:”code”,”execution_count”:null,”id”:”cfd010f4-866b-48ea-a758-63122dbfaa10″,”metadata”:{“id”:”cfd010f4-866b-48ea-a758-63122dbfaa10″},”outputs”:[],”source”:[]},{“cell_type”:”markdown”,”id”:”83f99a18-b4fa-449e-99fc-9c21ba52b960″,”metadata”:{“id”:”83f99a18-b4fa-449e-99fc-9c21ba52b960″},”source”:[“(c) Fit a ridge regression model on the training set, with $\lambda$ chosen by cross-validation. Report the test error obtained.n”]},{“cell_type”:”code”,”execution_count”:null,”id”:”0b2f4bd8-e985-4eb8-b000-c9a7d17fd234″,”metadata”:{“id”:”0b2f4bd8-e985-4eb8-b000-c9a7d17fd234″},”outputs”:[],”source”:[]},{“cell_type”:”markdown”,”id”:”0de95829-9475-4511-8d33-d94b46815899″,”metadata”:{“id”:”0de95829-9475-4511-8d33-d94b46815899″},”source”:[“(d) Fit a lasso model on the training set, with $\lambda$ chosen by crossvalidation. Report the test error obtained, along with the number of non-zero coefficient estimates.”]},{“cell_type”:”code”,”execution_count”:null,”id”:”64fc67bf-186a-4349-b863-c9bbe054bc4e”,”metadata”:{“id”:”64fc67bf-186a-4349-b863-c9bbe054bc4e”},”outputs”:[],”source”:[]},{“cell_type”:”markdown”,”id”:”6cb429ff-1e33-4cf4-8201-9ef8a80dee58″,”metadata”:{“id”:”6cb429ff-1e33-4cf4-8201-9ef8a80dee58″},”source”:[“(e) Comment on the results obtained. How accurately can we predict the number of college applications received? Is there much difference among the test errors resulting from these five approaches?”]},{“cell_type”:”code”,”execution_count”:null,”id”:”ff2e5696-4070-4544-849a-b0b6db61382e”,”metadata”:{“id”:”ff2e5696-4070-4544-849a-b0b6db61382e”},”outputs”:[],”source”:[]}],”metadata”:{“kernelspec”:{“display_name”:”Python 3 (ipykernel)”,”language”:”python”,”name”:”python3″},”language_info”:{“codemirror_mode”:{“name”:”ipython”,”version”:3},”file_extension”:”.py”,”mimetype”:”text/x-python”,”name”:”python”,”nbconvert_exporter”:”python”,”pygments_lexer”:”ipython3″,”version”:”3.10.0″},”colab”:{“provenance”:[]}},”nbformat”:4,”nbformat_minor”:5}
Requirements: normal