we easily learn the MEAN of Statics of class 10th
Category: Statistics
-
Hi pleas I need help for my homework
Progress Check
Use this activity to assess whether you and your peers can:
- Create a contingency table in StatCrunch.
- Use conditional percentages to analyze the data in a contingency table.
- Draw conclusions based on the analysis of the data in a contingency table.
Directions
Use the drop-down menu to learn about the three steps needed to complete this assignment.
Three steps to complete the assignment
Step 1: Review the Rubric
- Before you submit your work, review the rubric at the bottom of this assignment.
- Use the rubric as a checklist to determine whether you are ready to submit your work.
Step 2: First Draft
- Commit a good-faith effort to address each item in the Prompt section below.
- Please be sure to number your responses and include “white space” between problem numbers. This improves the readability and flow of your work. I cannot give feedback and grade jumbled work.
- Use either of the following options to submit your work.
OPTION 1: You can submit a text-entry assignment (i.e. typing your answers in Canvas). To learn how to submit a text-entry assignment, use these (opens in a new tab).
OPTION 2: You can upload your paper-and-pencil work (or the digital equivalent). To learn how to upload your paper-and-pencil work, use these (opens in a new tab). WARNING – some file types may not be visible on my end. So to learn which files you can upload, be sure to use the directions link I provided for this option. - Not ready to submit a good-faith effort yet? Avoid frustration – use the link to the Questions, Answers, & Tips discussion board (at the bottom of this page) to post questions about this assignment (or visit the discussion board to answer your classmates’ questions). You can also contact me directly (see the homepage for my contact information).
Step 3: Optional Final Draft
- After you submit your good-faith attempt to fully respond to the questions in the Prompt section below, advance to the ANSWER(S) page.
- You can use the ANSWER(S) page to correct your work and resubmit this assignment any time before I begin grading the problems. However, to earn full credit, you are not required to submit a final draft for this assignment. But if you do submit a final draft, I will only grade it if you submitted a good-faith effort on your first draft.
- Warning – I will only grade your most recent submission. So if you choose to submit a final draft, please do not leave anything out, and please do not direct me to read an earlier submission. To maximize your score, your most recent submission (at the time I begin grading) must be complete.
Context
Clinical depression is a recurrent illness requiring treatment and often hospitalization. Nearly 50% of people who have an episode of major depression will have a recurrence within 2-3 years. Being able to prevent the recurrence of depression in people who are at risk for the disease would go a long way to alleviate the pain and suffering of patients.
During the 1980s the federal government, through the National Institutes of Health (NIH), sponsored a large clinical trial to evaluate two drugs for depression. There were 3 treatment groups. Patients received either Imipramine (Imip), Lithium (Li), or a Placebo (Pl). Researchers randomly assigned patients to one of the 3 treatment groups and followed them for 2-4 years to track any recurrences of depression.
(Prien et al., Archives of General Psychiatry, 1984).
Variables
- Hospt: Which hospital the patient was from: Labeled 1, 2, 3, 5 or 6
- Treat: 0=Lithium; 1=Imipramine; 2=Placebo
- Outcome: 0=Success 1=Failure (recurrence of depression)
- Time: Number of weeks until a recurrence (if outcome=1) or until study ended (if outcome=0)
- AcuteT: How long the patient was depressed before the start of the current study, measured in days
- Age: Age in years
- Gender: 1=Female 2=Male
Data
- If you have not already done so, open the depression data set in the Stats at Cuyamaca College group on StatCrunch ( – opens in a new tab).
Prompt
We will analyze the data to answer the 1st research question: Which of the drugs (if either) was more successful in preventing the recurrence of depression relative to the placebo?
In the previous lab-preparation activity, we determined that we will analyze the data using a two-way table and conditional percentages.
Question 1
Use StatCrunch to produce a two-way contingency table. ()
To create a meaningful table with your response, complete each of the following.-
-
- Copy the table in your StatCrunch output window and paste it into the textbox. ()
- After you paste the content of your StatCrunch output window into the textbox, keep the table titled Contingency table results: and delete the Chi-Square results: table.
- Make your contingency table more meaningful to the reader. Use the Treat and Outcome variable descriptions (provided above in the Variables section) to replace the numeric row labels and the numeric column labels with meaningful words. How do we replace the row and column labels? After you copy and paste the contingency table into your response, click in an appropriate table cell, delete the numeric label, and type the appropriate “word” label.
-
Question 2
Analyze the data in your two-way table by finding appropriate conditional percentages. Write each conditional percentage as a ratio (e.g. 25 out of 40) and as a percentage (e.g. 25/40 = 62.5%). Then write a sentence that explains the meaning of the percentage in the context of the research question.
Question 3
Draw a conclusion. Based on this study, which drug was the most effective in preventing the recurrence of depression? Support your conclusion using conditional percentages.
List of StatCrunch Directions
Click here for StatCrunch Directions
Each link will open in a new window. To return to this assignment, either close the new tab or select the tab for this assignment.
- (You only need to do this once.)
- (open your random sample)
- (no screenshots; please use these directions)
- (no attachments; please use these directions)
Here is a PDF document with all .
Module 11 Discussion Board
Use the Module 11 (opens in a new tab) to ask questions or provide feedback about the problems in any Module 11 activity – including this peer-reviewed assignment.
Review Feedback
- Instructor feedback is only available after an assignment is graded.
- Use these (opens in a new tab) to learn how to review feedback.
Click the “Next” or > button to continue.
Content by Cuyamaca College math faculty and licensed under the .
Rubric
Formative Assessments w/ StatCrunch
Formative Assessments w/ StatCrunch
Criteria Ratings Pts This criterion is linked to a Learning OutcomeAnswering the Prompt
8 pts
This criterion is linked to a Learning OutcomeStatCrunch
2 pts
Total Points: 10
-
The Relationship Between Financial Literacy and Wealth Accum…
Topic: The Relationship Between Financial Literacy and Wealth Accumulation Among African American Households in the United States. Formatting: Double spaced, APA format, font size 12, Times New Roman. Report must be at least 10 pages. No maximum page limit. Sections to Include: Introduction and Problem Description (2+ pages) Explain the problem you’re addressing and the purpose of your project. Describe the source of the dataset, how you collected it, and what kind of data you used. Provide a list or table of the variables (data points) you used to solve the problem. Example: If youre studying how weather impacts sales, list variables like Temperature, Rainfall, and Sales. Techniques Used to Analyze Data (2+ pages) Describe what data analysis methods you applied to the dataset to answer your problem. (e.g., regression, clustering) or explore new ones. Example: Linear regression can be applied to analyze how financial literacy affects investment participation and wealth accumulation among African American households.. Results (1+ page) Present your findings using graphs, figures, or outputs from Excel or R. Explain what the results show in relation to your problem. Do they support your initial questions or not? Example: Show a scatter plot of financial literacy scores versus income and explain whether higher financial literacy is associated with higher income levels among African American households. Challenges and Summary (1+ page) Describe any difficulties you faced in the project and summarize what you learned. Appendix (Optional) If needed, add any detailed steps, such as Excel formulas or R code, here. References : here are a few FINRA Investor Education Foundation FINRA Investor Education Foundation. (2024). National Financial Capability Study. Financial Literacy Research Lusardi, A., & Mitchell, O. (2014). The economic importance of financial literacy: Theory and evidence. Journal of Economic Literature, 52(1), 544. Federal Reserve Wealth Data Board of Governors of the Federal Reserve System. (2023). Survey of Consumer Finances. U.S. Census Data (Wealth / Demographics) U.S. Census Bureau. (2023). American Community Survey. -
Statistics Question
as file shown
-
Data analysis project
This assignment is a quiz! So I would have to give you my login information
-
Descriptive statistics and data analysis
No instructions provided
-
Statistics Question
Instructions
Work through this quiz to prepare for the Module 11 – Treating Depression Lab Part 1. This activity is included in the Labs and Other Activities portion of your grade. You have an unlimited number of attempts. To prepare for the lab, you must review each attempt and use the feedback to retake the quiz until you earn 100%. In other words, you cannot move on until you earn 100% on this quiz. But don’t let your good productive struggle devolve into frustration. If you carefully reviewed the feedback after two attempts, and you still haven’t earned 100%, use the discussion board below to ask for help. Give your peers or me some time to respond. Then return to the discussion board, review the responses, and try again. Or you can also contact me directly. My contact information is on the homepage of our course in Canvas.
Prepare for the Online Lab
Use this activity to:
- Obtain information from a spreadsheet.
- Identify the explanatory variable and the response variable.
- Select an appropriate visual display to summarize the data.
- Select the appropriate numerical summaries to summarize the data.
Below is the information you will find in the lab on the next page (after you finish this preparation quiz).
Context
Clinical depression is a recurrent illness requiring treatment and often hospitalization. Nearly 50% of people who have an episode of major depression will have a recurrence within 2-3 years. Being able to prevent the recurrence of depression in people who are at risk for the disease would go a long way to alleviate the pain and suffering of patients.
During the 1980’s the federal government, through the National Institutes of Health (NIH), sponsored a large clinical trial to evaluate two drugs for depression. There were 3 treatment groups. Patients received either Imipramine (Imip), Lithium (Li), or a Placebo (Pl). Researchers randomly assigned patients to one of the 3 treatment groups and followed them for 2-4 years to track any recurrences of depression.
(Prien et al., Archives of General Psychiatry, 1984).Variables
- Hospt: Which hospital the patient was from: Labeled 1, 2, 3, 5 or 6
- Treat: 0=Lithium; 1=Imipramine; 2=Placebo
- Outcome: 0=Success 1=Failure (no recurrence of depression)
- Time: Number of weeks until a recurrence (if outcome=1) or until study ended (if outcome=0)
- AcuteT: How long the patient was depressed before the start of the current study, measured in days
- Age: Age in years
- Gender: 1=Female 2=Male
Data
- Open the depression data set in the Stats at Cuyamaca College group on StatCrunch ( – opens in a new tab).
Prompt
In this quiz, you’ll explore the depression datafile in StatCrunch and familiarize yourself with the first research question related to this study. In the next activity you’ll use StatCrunch to investigate the first research question.
Module 11 Discussion Board
Use the Module 11 (opens in a new tab) to ask questions or provide feedback about the problems in any Module 11 activity – including this quiz. Question 10 / 1.3 pts
Examine the spreadsheet of data in StatCrunch. Out of the first ten individuals in the datafile, how many had a recurrence of depression during the study?
Incorrect. You want the number of patients who had a recurrence of depression (Outcome = 1) out of the first ten patients.
IncorrectQuestion 20 / 1.4 pts
Examine the spreadsheet of data in StatCrunch. Out of the first ten individuals in the datafile who were assigned to the Lithium treatment group, how many had a recurrence of depression during the study?
Incorrect. Look at the first ten patients who were in the Lithium treatment group (Treat = 0). Then count the number out of those ten Lithium patients who had a recurrence of depression (Outcome = 1) during the study.
Did you think the answer was 2? Be careful. This question is not about just the first 10 people in the spreadsheet. It’s about the first 10 people who had the lithium treatment. So you may need to keep looking past the first 10 people in the spreadsheet.
It may be helpful to highlight the Lithium patients (Treat = 0) until you have found the first 10 Lithium patients.
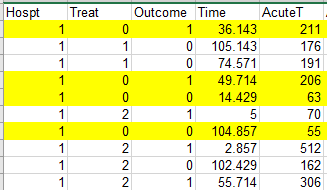
IncorrectQuestion 30 / 1.3 pts
Examine the spreadsheet of data in StatCrunch. How many days was the first male in the datafile depressed before the start of the study?
Incorrect. Find the first male in the datafile (Gender = 2). Then look at his AcuteT, the number of days he was depressed before the start of the study.
PartialQuestion 43 / 6 pts
Here is the first research question related to the study:
Which of the drugs (if either) was more successful in preventing the recurrence of depression relative to the placebo?
The explanatory variable is Treat , and it is a categorical variable.
The response variable is Outcome , and it is a quantitative variable.
To answer the research question, you will analyze the data. Which visual graph or table is appropriate for your analysis? Side-by-side boxplots
Which of the following is an appropriate numerical summary to include in your analysis? Descriptive statistics (mean, median, etc.)
Answer 1:
Correct. Treat represents the treatment groups (Lithium, Imipramine, and placebo). To answer the question, we must compare the different drugs (treatments). So Treat is the explanatory variable.
Answer 2:
categorical
Correct. The values of this explanatory variable are numeric, but the numbers define categories (0=Lithium; 1=Imipramine; 2=Placebo), so it is a categorical variable.
Answer 3:
Correct. Outcome represents whether the drug/placebo was successful (Outcome=0) in preventing the recurrence of depression or not (Outcome=1)
Answer 4:
Incorrect. The response variable indicates whether the treatment was successful or not, so it is a categorical variable with the categories success and failure.
Answer 5:
Side-by-side boxplots
Incorrect. We use side-by-side boxplots to compare a single quantitative variable across multiple groups of a categorical variable. We are not analyzing a quantitative variable.
Answer 6:
Descriptive statistics (mean, median, etc.)
Incorrect. We use descriptive statistics such as mean, median, standard deviation, IQR, etc. to describe the distribution of a single quantitative variable across multiple groups of a categorical variable.
Treat and Outcome are two categorical variables.
-
Maths chapter
What is the formula of mean
-
Week 4 Discussion responses
Please respond to the follow people. Per my professor “a substantive post should follow this criterion: Integrate theory and research; include specific examples and/or substantiating evidence because it is important to acknowledge how others contributed to your reply; include in-text citations and references in the APA format. Demonstrate proper spelling, grammar, and scholarly tone.”
Please site some sources from my textbook and please add page numbers
Sullivan, M., III. (2025). Statistics: Informed decisions using data (7th ed.). Pearson.
Respond #1 (Jett)
In this, the goal is to compare the average number of chocolate chips in Chips Amor cookies (Cookie A) and the grocery store brand cookies (Cookie B). As a product manager for Chips Amor, the purpose of this test is to determine whether the company’s claim that their cookies contain more chocolate chip is accurate. By collecting data and analyzing it statistically, the company can better understand if their product truly offers more value to customer.
The null hypothesis () states that the is no difference in the average number of chocolate chips between the two cookies. ().
This research hypothesis is () states that Chips Amor cookies contain more chocolate than the grocery store brand cookies. ().
The population being studied include all Chips Amor cookies produced by the company and all the cookies produced by the grocery store brand. The sample used for this test included 30 cookies that participants counted during the experiment. Each participant counted the number of chocolate chips in both cookies, allowing the researcher to compare the differences.
Because the hypothesis predicts that Chips Amor cookies will contain more chips, this is considered a one-tailed test. After calculating the differences between Cookie A and Cookie B, the average difference was about 1.83 chips, meaning Chips Amor typically had almost two more chips per cookie. The t-test value was 4.85, and the p-value was 0.00002. Since the p-value is much smaller than the significance level of 0.05, the null hypothesis is rejected. There is strong evidence that Chips Amor cookies contain more chips than grocery store brands. The histogram also shows that most of the difference are positive, which visually supports the statistical results. As a product manager, this information could be used to support marketing claim, improve customer confidence, and show that the product delivers more chocolate chips than competitors.
Respond #2 (Dero)
Key statistics from the data:
- Mean chips in Cookie A (Chips Amor) = 23.33
- Mean chips in Cookie B (Store Brand) = 21.50
- t-statistic = 4.85
- p-value 0.000038
Parameters Being Compared
The parameters being compared are the average number of chocolate chips in Chips Amor cookies versus the average number in the local grocery store brand cookies. In statistical terms, we are comparing the population mean number of chips (A and B) for the two brands.
Null and Alternative Hypotheses
Null Hypothesis (H0): The average number of chocolate chips in Chips Amor cookies is equal to the average number in the grocery store cookies.
H0: A = B
Research/Alternative Hypothesis (H1): Chips Amor cookies contain more chocolate chips on average than the grocery store cookies.
H1: A > B
Because the claim is that Chips Amor has more chips, this is a one-tailed test.
Populations
The samples come from two populations:
- All Chips Amor cookies produced by the company
- All cookies produced by the local grocery store brand
The 30 cookies examined represent samples from those populations.
Randomness and Independence
The cookies can reasonably be treated as random samples if they were selected without bias from production batches. The samples are also independent, since each cookies chip count does not affect another cookie.
Interpretation as a Product Manager
As a product manager for Chips Amor, this data would be encouraging. The average cookie from Chips Amor has about 1.83 more chocolate chips per cookie than the store brand. The very small p-value (0.000038) indicates that this difference is statistically significant and unlikely to have happened by chance. This would support marketing claims that Chips Amor cookies contain more chocolate chips.
Other Real-World Conclusions
This research could help support advertising claims, quality control, and product differentiation. It could also justify pricing the product slightly higher if customers perceive more value.
Other Situations Where This Method Is Useful
This type of hypothesis testing is commonly used in:
- Food product comparisons (ingredients, size, quality)
- Medical studies comparing two treatments
- Employee productivity comparisons
- Education research comparing teaching methods
Experiments like this are also similar to taste tests, product testing panels, and consumer research studies used by many companies before launching marketing campaigns.
-
Standard Statistics in Statistics – 3 pages
Collect data for the subject I gave you a picture of cybersecurity income it needs to have a numeric value that can analyzed measuring mean and std deviation.
use one the listed links shown in the pictures. One word document that covers all of the instructions and write a claim about the data. Example shown in pics. Add 30 values for the data. Lastly an excel document that shows all of the data numbers and everything false not covered on the word document